BeyondMoore
Pioneering the Future of Computing

PI: Assoc. Prof. Didem Unat
Email: dunat@ku.edu.tr

PhD Student: Ilyas Turimbetov (iturimbetov18@ku.edu.tr)
Research Focus: Task graphs, load balancing.

PhD Student: Javid Baydamirli (jbaydamirli21@ku.edu.tr)
Research Focus: Compilers, parallel programming models.

PhD Student: Doǧan Sağbili (dsagbili17@ku.edu.tr)
Research Focus: Multi-device communication mechanisms.

PhD Student: Mohammad Kefah Taha Issa (missa18@ku.edu.tr)
Research Focus: Peer to peer GPU tracing and profiling.

PhD Student: Erdem Ege Maraşlı (emarasli26@ku.edu.tr)
Research Focus: Tracing and profiling of multi-gpu communication

PhD Student: Amin Ansari (mansari26@ku.edu.tr)
Research Focus: Performance optimization of inference workloads.

Master Student: Sinan Ekmekçibaşı (sekmekcibasi23@ku.edu.tr)
Research Focus: Multi-GPU Communication Models.

Master Student: Emre Düzakın (eduzakin18@ku.edu.tr)
Research Focus: LLM Based Multi Agent Systems.

Master Student: Hanaa Zaqout (hzaqout25@ku.edu.tr)
Research Focus: Multi-GPU Communication Models.

Alumni: Ismayil Ismayilov
Research Focus: Taming heterogeneity, programming models.

Alumni: Muhammed Abdullah Soytürk
Research Focus: Scalable deep learning.

Alumni: Dr. Muhammad Aditya Sasongko
Research Focus: Performance models, profiling tools.
Compiler, Runtime and Execution Models
- CPU-Free Execution Model: a fully autonomous execution model for multi-GPU applications
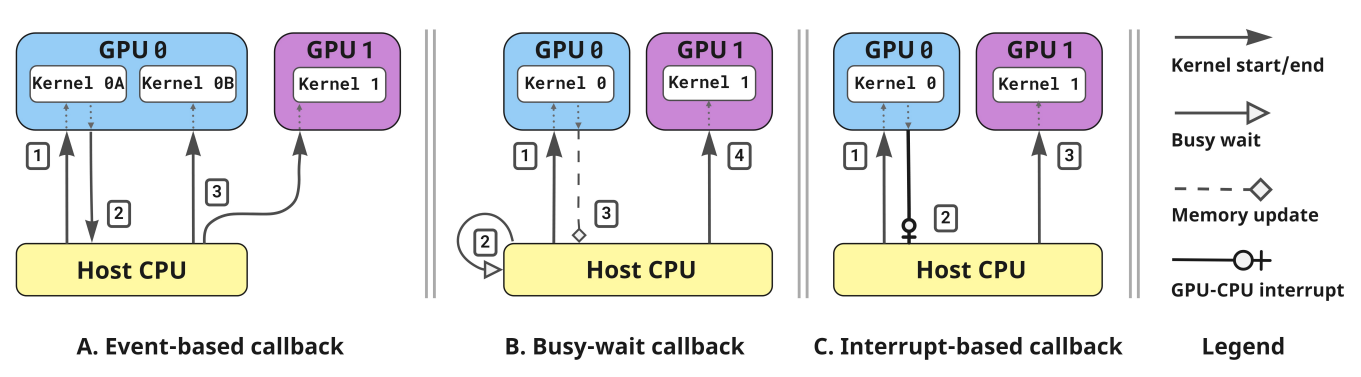
- Multi-GPU Callbacks: GPU to CPU callback mechanisms
- CPU-Free Task Graph: a lightweight runtime system tailored for CPU-free task graph execution
- CPU-Free Compiler: compiler for generating CPU-Free multi-GPU code
- Unified Communication Library: a unified communication library for device-to-device communication
Profiling Tools
- Snoopie: A Multi-GPU Communication Profiler and Visualiser
- PES AMD vs Intel: A Precise Event Sampling Benchmark Suite
- ucTrace: A Multi-Layer Profiling Tool for UCX-driven Communication
Algorithms and Applications
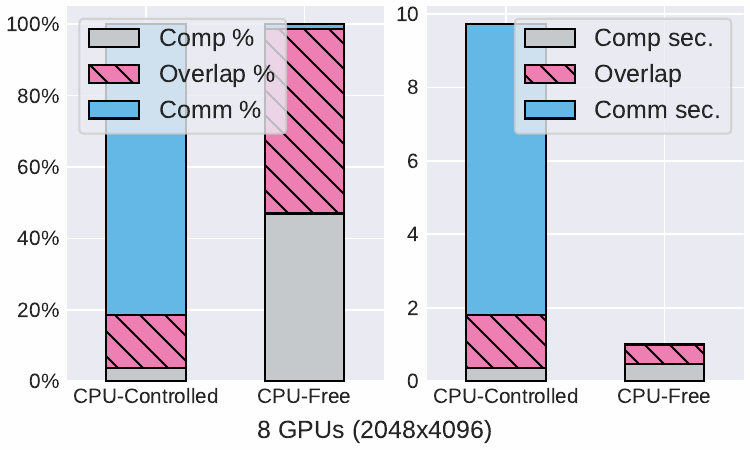
This project introduces a fully autonomous execution model for multi-GPU applications, eliminating CPU involvement beyond initial kernel launch. In conventional setups, the CPU orchestrates execution, causing overhead. We propose delegating this control flow entirely to devices, leveraging techniques like persistent kernels and device-initiated communication. Our CPU-free model significantly reduces communication overhead. Demonstrations on 2D/3D Jacobi stencil and Conjugate Gradient solvers show up to a 58.8% improvement in communication latency and a 1.63x speedup for CG on 8 NVIDIA A100 GPUs compared to CPU-controlled baselines.
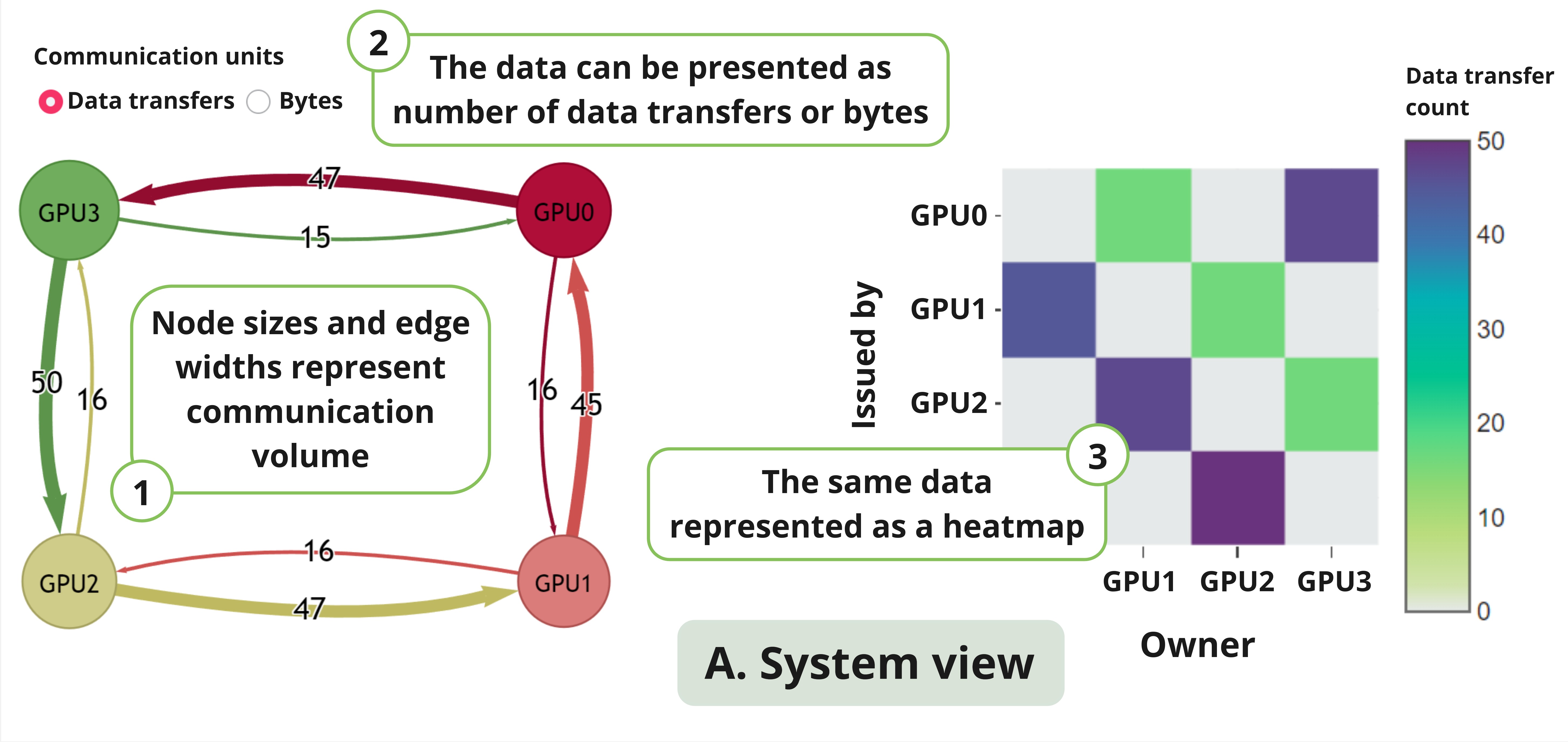
With data movement posing a significant bottleneck in computing, profiling tools are essential for scaling multi-GPU applications efficiently. However, existing tools focus primarily on single GPU compute operations and lack support for monitoring GPU-GPU transfers and communication library calls. Addressing these gaps, we present Snoopie, an instrumentation-based multi-GPU communication profiling tool. Snoopie accurately tracks peer-to-peer transfers and GPU-centric communication library calls, attributing data movement to specific source code lines and objects. It offers various visualization modes, from system-wide overviews to detailed instructions and addresses, enhancing programmer productivity.
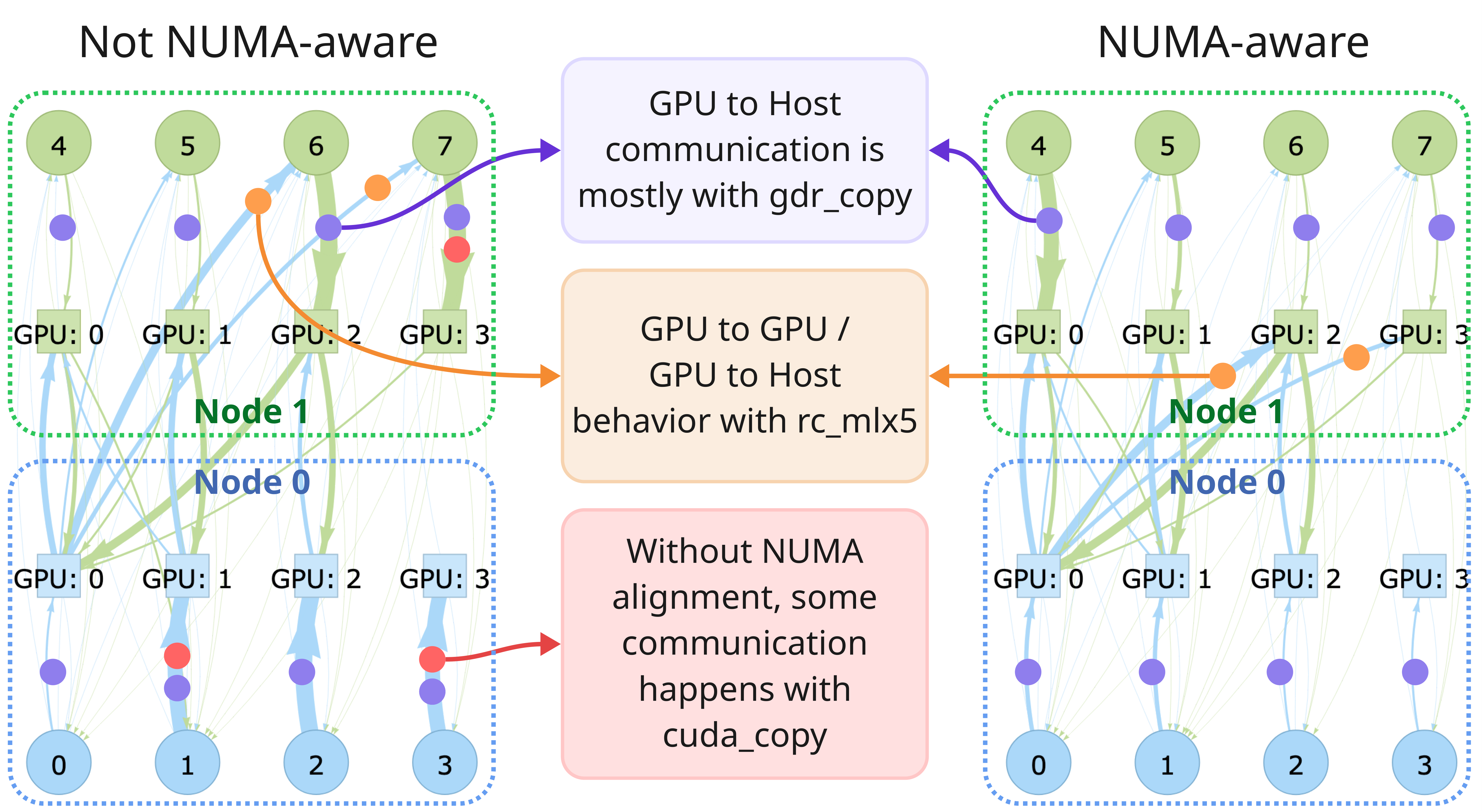
We introduce ucTrace, a novel profiler that exposes and visualizes UCX-driven communication in HPC environments. ucTrace provides insights into MPI workflows by profiling message passing at the UCX level, linking operations between hosts and devices (e.g., GPUs and NICs) directly to their originating MPI functions. Through interactive visualizations of process- and device-specific interactions, ucTrace helps system administrators, library and application developers optimize performance and debug communication patterns in large-scale workloads. We demonstrate ucTrace's features through a wide range of experiments including MPI point-to-point behavior under different UCX settings, Allreduce comparisons across MPI libraries, communication analysis of a linear solver, NUMA binding effects, and profiling of GROMACS MD simulations with GPU acceleration at scale.
To address resource underutilization in multi-GPU systems, particularly in irregular applications, we propose a GPU-sided resource allocation method. This method dynamically adjusts the number of GPUs in use based on workload changes, utilizing GPU-to-CPU callbacks to request additional devices during kernel execution. We implemented and tested multiple callback methods, measuring their overheads on Nvidia and AMD platforms. Demonstrating the approach in an irregular application like Breadth-First Search (BFS), we achieved a 15.7% reduction in time to solution on average, with callback overheads as low as 6.50 microseconds on AMD and 4.83 microseconds on Nvidia. Additionally, the model can reduce total device usage by up to 35%, improving energy efficiency.
We implemented a unified, portable high-level C++ communication library called Uniconn that supports both point-to-point and collective operations across GPU clusters. Uniconn enables seamless switching between communication backends (MPI, NCCL/RCCL, and NVSHMEM) and APIs (host or device) with minimal or no changes to application code. We evaluate its performance using network benchmarks, a Jacobi solver, and a Conjugate Gradient solver. Across three supercomputers, Uniconn incurs negligible overhead, typically under 1 % for the Jacobi solver and under 2% for the Conjugate Gradient solver.
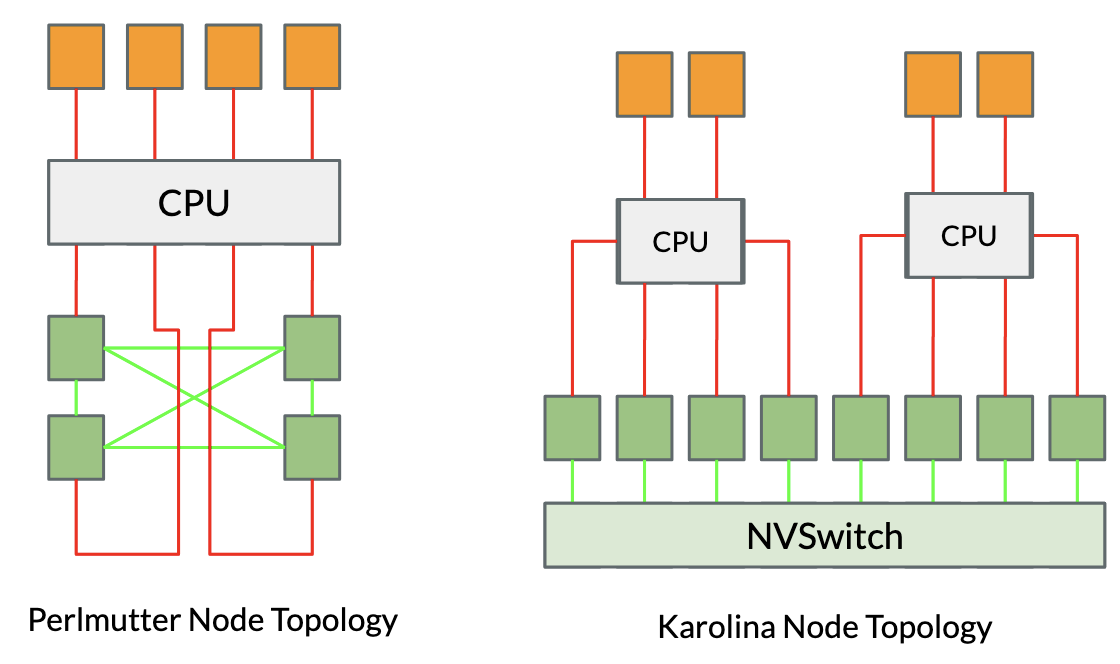
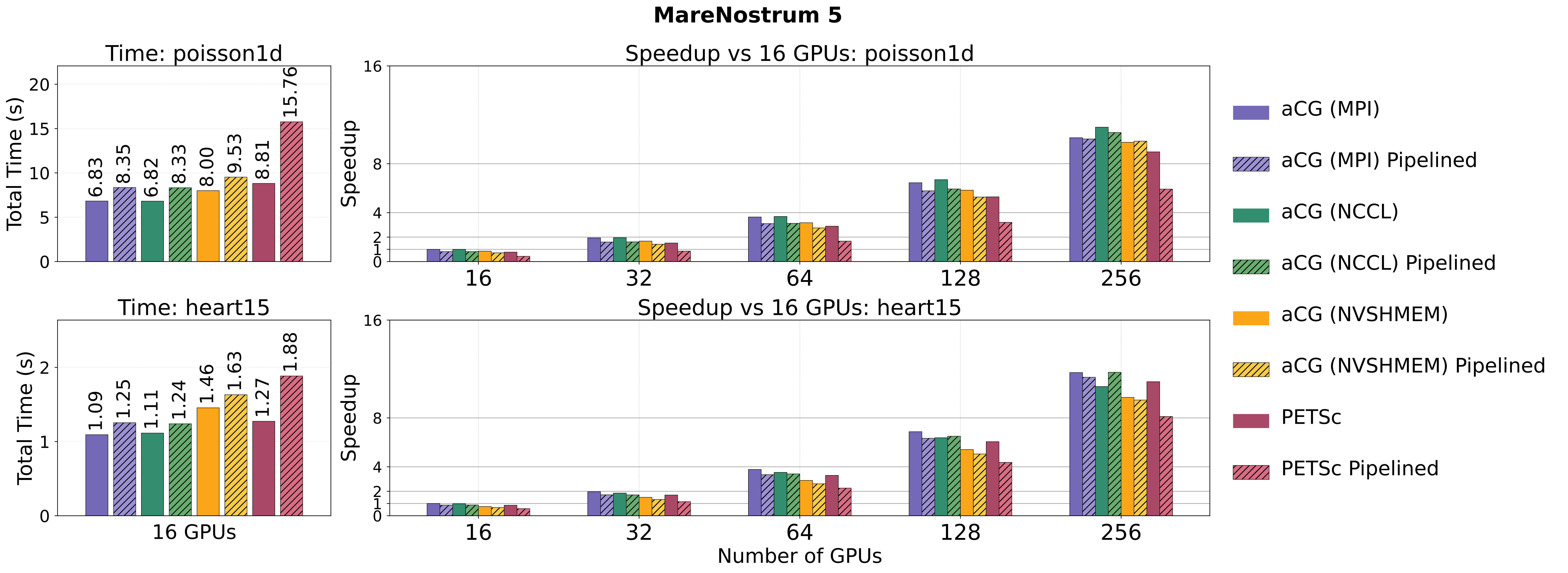
This work revisits Conjugate Gradient (CG) parallelization for large-scale multi-GPU systems, addressing challenges from low computational intensity and communication overhead. We develop scalable CG and pipelined CG solvers for NVIDIA and AMD GPUs, employing GPU-aware MPI, NCCL/RCCL, and NVSHMEM for both CPU- and GPU-initiated communication. A monolithic GPU-offloaded variant further enables fully device-driven execution, removing CPU involvement. Optimizations across all designs reduce data transfers and synchronization costs. Evaluations on SuiteSparse matrices and a real finite element application show 8–14% gains over state-of-the-art on single GPUs and 5–15% improvements in strong scaling tests on over 1,000 GPUs. While CPU-driven variants currently benefit from stronger library support, results highlight the promising scalability of GPU-initiated execution for future large-scale systems.
We're actively crafting a compiler to empower developers to write high-level Python code that compiles into efficient CPU-free device code. This compiler integrates GPU-initiated communication libraries, NVSHMEM for NVIDIA and ROC_SHMEM for AMD, enabling GPU communication directly within Python code. With automatic generation of GPU-initiated communication calls and persistent kernels, we aim to streamline development workflows.
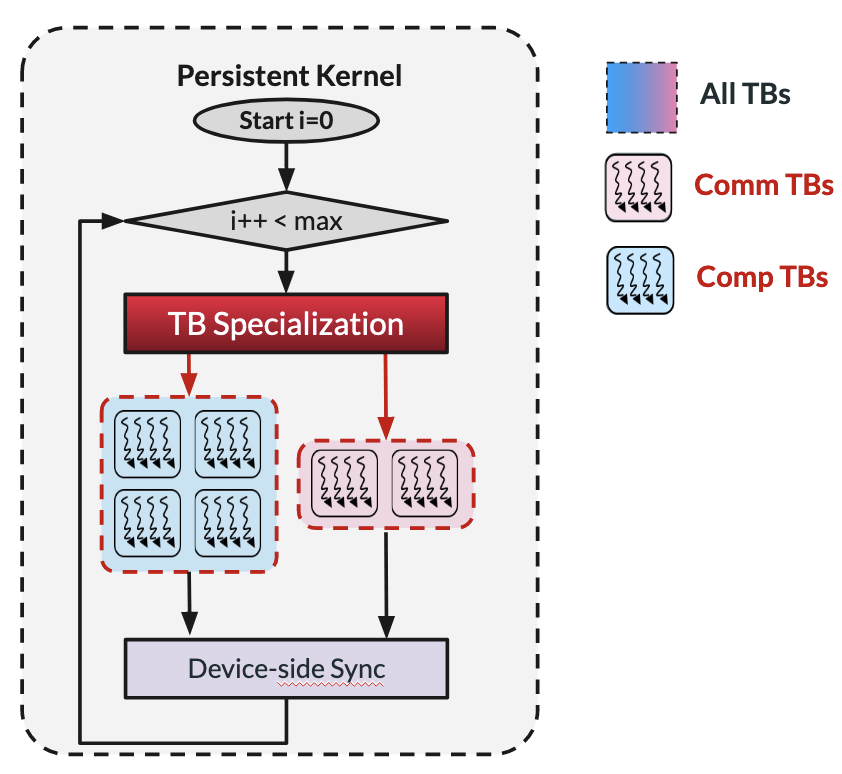
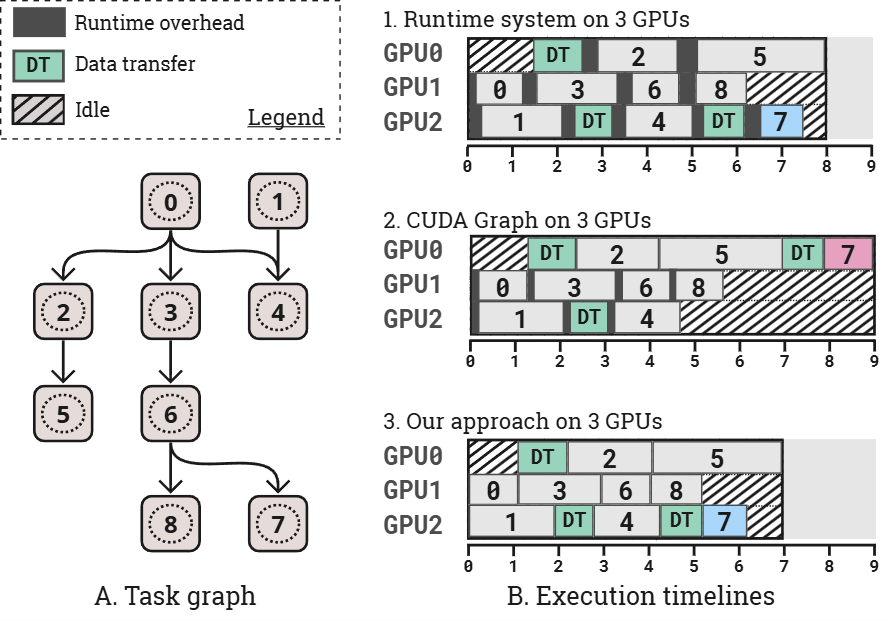
We've designed and implemented a lightweight runtime system tailored for CPU-free task graph
execution in multi-device systems. Our runtime minimizes CPU involvement by handling task graph initialization
exclusively, while executing all subsequent operations on the GPU side. This runtime system provides online
scheduling of graph nodes, monitors GPU resource usage, manages memory allocation and data transfers, and
synchronously tracks task dependencies. By accepting computational graphs as input, originally designed for single
GPUs, it seamlessly scales to multiple GPUs without necessitating code modifications.
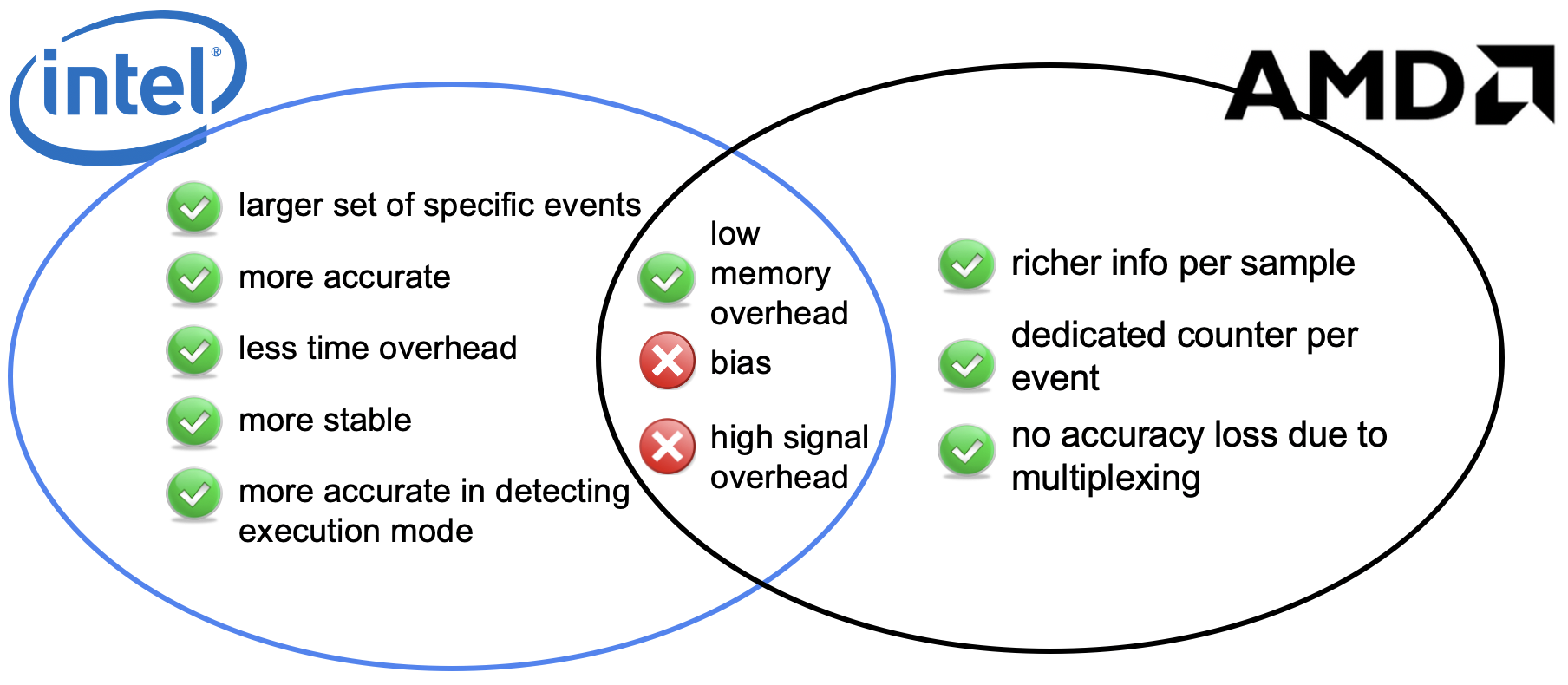
Precise event sampling, a profiling feature in commodity processors, accurately pinpoints instructions triggering hardware events. While widely utilized, support from vendors varies, impacting accuracy, stability, overhead, and functionality. Our study benchmarks Intel PEBS and AMD IBS, revealing PEBS's finer-grained accuracy and IBS's richer information but lower stability. PEBS incurs lower time overhead, while IBS suffers from accuracy issues. OS signal delivery adds significant time overhead. Both PEBS and IBS exhibit sampling bias. Our findings hold in a full-fledged profiling tool on modern Intel and AMD machines. This comparison offers valuable insights for hardware designers and profiling tool developers.
All the artifacts and benchmarks can be found here.